Getting started with musif¶
Download the Getting started tutorial Jupyter notebook here
musif is a Python library to analyze music scores. It is a tool to massively extract features from MusicXML and MuseScore files.
musif was born in the context of the ERC Project “DIDONE” and, consequently,
it is specialized in 18th-century Italian opera arias. However, it is also prepared to work with other repertoires.
This tutorial is an introduction for people who are not experts in programming. If you are already an expert, just skip to the Data Section and then go to the Advanced Tutorial.
Installation¶
First, you should install Python > 3.10. An easy way to do this is by using Anaconda, especially if you are not used to commandline interface.A
Once you have installed anaconda:
Launch the
anaconda-navigatorCreate an environment selecting python version >= 3.10
Switch to the newly created environment by clicking on its name
To install musif:
Start
jupyterin your Anaconda environment.Open this tutorial.
Run the following cell by clicking on it and pressing Ctrl+Enter.
Here, the ! is a special command that executes commands in the terminal. After having run it, you may need to restart the notebook (click the circular arrow ↻ in the top bar, near the icons ▶ and ⏹)
To run this tutorial:
In the
Hometab of theanaconda-navigator, select “All applications” and the newly created environment in the options at the top.Click on
Install, near to theJupytericonOnce installed, click on
launchnear thenotebookicon; a web interface will open in the browserDownload by clicking iwth right mouse button and selecting “save as…”
Navigate to the downloaded file from the web interface and open it
Run the following cell by clicking on it and pressing Ctrl+Enter
! pip install musif
import musif
print('Version: ', musif.__version__)
Version: 1.2.3
Introduction¶
If you are new to Python, we suggest you to read an introductory tutorial for it, for instance, this one.
In the following, we will introduce some technical terminology that may be useful to you to understand technical documentation while working with musif:
A function is a way to represent code that is convenient for humans. You can think of functions as mathematical functions, with some input and some output. However, some programming languages call them procedures; this is not the case with Python, but this name allows grasping what functions are, after all: successions of commands that the computer has to execute.
An object is a computational way to represent information and code in the memory of computers; you can think of objects as real concepts of the real world: objects have properties (in Python named fields) and functionalities (named methods). For instance, an object could be a vehicle, which has some properties (length, maximum speed, number of wheels) and some functionalities (accelerate, decelerate, stop). Objects can also have specializations (named children): in our example, a child of vehicle could be the car and another child could be the bike: they have different properties and apply the functionalities in a different way. Both the vehicle, the car, and the bike may have instances: the car that you use everyday to go to work is different from your friend’s even if they have the same exact properties, because they are two different concrete objects. Technically, those two cars are two instances of the same class. To create an instance, you have to call a function, generically named constructor, which takes as arguments the class and the other properties. This function will return the instance. To use
musif, you don’t need to know a lot about objects, but while you search the web it is good to have a little of knowledge.A DataFrame is another way to represent information for computers. They are designed to be extremely efficient, even if sometimes some aspects of the information can get lost. They are mainly used for data science problems. You can think of a DataFrame as a table, with rows and columns. Usually, rows are instances while columns are properties. In data science, these words often become samples and features/variables. A typical operation is to select only certain columns (properties) or only certain rows (instances) to select subset of the data or to modify the data itself.
Don’t be scared to use web search engines such as Google: searching the web in a proper way is one of the most important skills a programmer has!
Main objects¶
When using musif, you will usually interface with two objects:
FeaturesExtractor(), which reads music scores and computes a DataFrame containing all the extracted features. In the simplest case, each row represents a music score, while each column represents a feature.DataProcessor(), which takes the DataFrame with all the features in it and post-processes it to clean, improve, and possibly modify some of the features.
These two objects take as input two different configurations that modify their behavior. In other words, the constructors of FeaturesExtractor and DataProcessor can accept a wide range of arguments.
But let’s proceed step by step!
import urllib.request
import zipfile
from pathlib import Path
data_dir = Path("data")
dataset_path = "dataset.zip"
urllib.request.urlretrieve("https://zenodo.org/record/4027957/files/AnatomyComposerAttributionMIDIFilesAndFeatureData_1_0.zip?download=1", dataset_path)
with zipfile.ZipFile(dataset_path, 'r') as zip_ref:
zip_ref.extractall(data_dir)
data_dir = data_dir / Path('AnatomyComposerAttributionMIDIFilesAndFeatureData_1_0') / Path('MIDI/')
Configuration¶
Let’s create a configuration for our experiment. Configurations can be expressed using a yaml file or with key-value arguments. yaml files are designed for complex projects, while key-value arguments are perfect for simple situations like this.
Key-value arguments are something similar to a dictionary: There is a key which must be unique in the dictionary; each key is associated with a value, which can be repeated. Python can retrieve a value using its key in a very efficient way!
First, we’ll need to import the class that describes how a configuration is:
from musif.config import ExtractConfiguration
config = ExtractConfiguration(
None,
data_dir = data_dir,
basic_modules=["scoring"],
features = ["core", "ambitus", "melody", "tempo",
"density", "texture", "lyrics", "scale",
"key", "dynamics", "rhythm"],
parallel = -1 #use > 1 if you wish to use parallelization (runs faster, uses more memory)
)
Now, we can call its constructor to obtain a configuration object:
Feature extraction¶
Now that we have our configuration, we pass it to the function that creates FeaturesExtraction objects. This function is exactly named FeaturesExtraction:
from musif.extract.extract import FeaturesExtractor
extractor = FeaturesExtractor(config)
Before starting the extraction, we also need to tell MuseScore the type of files it should look for. In this case, we want it to look for files with extension '.mid'. By default, it would look for .mscx files, so we need to change it:
Now, we can start the extraction using the method extract. It will return a DataFrame:
df = extractor.extract()
print('Shape df: ', df.shape)
df.head()
Shape df: (175, 927)
| FamilyGen_Density | FamilyGen_Notes | FamilyGen_NotesMean | FamilyGen_NumberOfFilteredParts | FamilyGen_NumberOfParts | FamilyGen_SoundingDensity | FamilyGen_SoundingMeasures | FamilyGen_SoundingMeasuresMean | FamilyInstrumentation | FamilyScoring | ... | SoundFl_TrimmedIntervallicMean | SoundFl_TrimmedIntervallicStd | SoundScoring | Tempo | TempoGrouped1 | TempoGrouped2 | TimeSignature | TimeSignatureGrouped | Voices | WindowId | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.113402 | 1.468171 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 1 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.165948 | 1.620333 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 2 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.106242 | 1.634416 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 3 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.095768 | 1.578589 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 4 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.073604 | 1.623796 | fl | <NA> | <NA> | None | 2/1 | other | 0 |
5 rows × 927 columns
df.set_index('Id', inplace=True)
df.drop(['level_0', 'index'], axis=1, errors = 'ignore', inplace = True)
print('Shape df: ', df.shape)
df.head()
Shape df: (175, 926)
| FamilyGen_Density | FamilyGen_Notes | FamilyGen_NotesMean | FamilyGen_NumberOfFilteredParts | FamilyGen_NumberOfParts | FamilyGen_SoundingDensity | FamilyGen_SoundingMeasures | FamilyGen_SoundingMeasuresMean | FamilyInstrumentation | FamilyScoring | ... | SoundFl_TrimmedIntervallicMean | SoundFl_TrimmedIntervallicStd | SoundScoring | Tempo | TempoGrouped1 | TempoGrouped2 | TimeSignature | TimeSignatureGrouped | Voices | WindowId | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Id | |||||||||||||||||||||
| 0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.113402 | 1.468171 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 1 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.165948 | 1.620333 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 2 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.106242 | 1.634416 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 3 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.095768 | 1.578589 | fl | <NA> | <NA> | None | 2/1 | other | 0 | |
| 4 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ww | ww | ... | -0.073604 | 1.623796 | fl | <NA> | <NA> | None | 2/1 | other | 0 |
5 rows × 926 columns
Finding features¶
Yey! We’ve successfully employed musif to extract the desired features from the scores. All of these features are now stored in the df variable, and we can access them from there.
How to find certain features? All types of features and their correspondent definitions can be found in https://musif.didone.eu/Feature_definition.html. There you can find each type of feature along with a regular expression (RegEx) and a brief explanation stating what that set of features describes.l To find a specific set of features based on its regex:
df.filter(regex='Part.+_Interval.+_Per')
| PartFlI_IntervalA-2_Per | PartFlI_IntervalA1_Per | PartFlI_IntervalA2_Per | PartFlI_IntervalA3_Per | PartFlI_IntervalA4_Per | PartFlI_IntervalM-2_Per | PartFlI_IntervalM-3_Per | PartFlI_IntervalM-6_Per | PartFlI_IntervalM-7_Per | PartFlI_IntervalM-9_Per | ... | PartFlI_IntervalsMajorDesc_Per | PartFlI_IntervalsMinorAll_Per | PartFlI_IntervalsMinorAsc_Per | PartFlI_IntervalsMinorDesc_Per | PartFlI_IntervalsPerfectAll_Per | PartFlI_IntervalsPerfectAsc_Per | PartFlI_IntervalsPerfectDesc_Per | PartFlI_IntervalsWithinOctaveAll_Per | PartFlI_IntervalsWithinOctaveAsc_Per | PartFlI_IntervalsWithinOctaveDesc_Per | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Id | |||||||||||||||||||||
| 0 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.114943 | 0.034483 | <NA> | <NA> | <NA> | ... | 0.172837 | 0.068966 | 0.034483 | 0.034483 | 0.512123 | 0.106447 | 0.101868 | 1.0 | 0.324497 | 0.371695 |
| 1 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.188312 | 0.045455 | <NA> | <NA> | <NA> | ... | 0.218958 | 0.162338 | 0.045455 | 0.116883 | 0.372618 | 0.105962 | 0.062201 | 1.0 | 0.360532 | 0.435014 |
| 2 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.245713 | 0.044699 | <NA> | <NA> | <NA> | ... | 0.282851 | 0.285156 | 0.109375 | 0.15 | 0.189659 | 0.045257 | 0.024475 | 1.0 | 0.404641 | 0.475432 |
| 3 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.137931 | 0.062069 | <NA> | <NA> | <NA> | ... | 0.191059 | 0.236842 | 0.075862 | 0.122807 | 0.375296 | 0.107478 | 0.068547 | 1.0 | 0.373753 | 0.426976 |
| 4 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.190211 | 0.055034 | <NA> | <NA> | <NA> | ... | 0.249377 | 0.190083 | 0.057851 | 0.132231 | 0.273048 | 0.084658 | 0.039822 | 1.0 | 0.415049 | 0.436383 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 170 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.214841 | 0.02509 | <NA> | <NA> | <NA> | ... | 0.243784 | 0.254902 | 0.108696 | 0.137255 | 0.282986 | 0.070828 | 0.051396 | 1.0 | 0.39817 | 0.441068 |
| 171 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.192255 | 0.048058 | <NA> | <NA> | <NA> | ... | 0.243046 | 0.275132 | 0.126984 | 0.142857 | 0.189175 | 0.064503 | 0.047243 | 1.0 | 0.479253 | 0.443318 |
| 172 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.196581 | 0.025641 | <NA> | <NA> | <NA> | ... | 0.24005 | 0.220588 | 0.101695 | 0.117647 | 0.244157 | 0.031732 | 0.034152 | 1.0 | 0.417226 | 0.404501 |
| 173 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.254902 | 0.039216 | <NA> | <NA> | <NA> | ... | 0.281809 | 0.19697 | 0.090909 | 0.106061 | 0.226009 | 0.051943 | 0.031067 | 1.0 | 0.408321 | 0.44868 |
| 174 | <NA> | <NA> | <NA> | <NA> | <NA> | 0.214286 | 0.038961 | <NA> | <NA> | <NA> | ... | 0.243536 | 0.220779 | 0.077922 | 0.133333 | 0.313252 | 0.084427 | 0.049106 | 1.0 | 0.374877 | 0.445405 |
175 rows × 66 columns
Post-processing¶
Most of the features we have computed actually need some post-processing, for instance to replace NaN with 0, merge columns, or remove features created while computing other features.
For this, we need a further step. In the next cell we will:
Instantiate a
DataProcessorobject using:the generated DataFrame
the default configuration (i.e.
Nonein place of the yaml file/configuration object)
Call the method
process()of that object to start the post-processing of the featuresWe retrieve the post-processed data from the field
dataWe print the size of the DataFrame.
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False
# Check if in colab
if IN_COLAB:
print('in colab')
import urllib.request
# Replace with the raw URL of the YAML file on GitHub
github_url = "https://raw.githubusercontent.com/DIDONEproject/musif/main/config_postprocess_example.yml"
# Replace with the desired local file name
local_file_name = "config_postprocess_example.yml"
urllib.request.urlretrieve(github_url, local_file_name)
print(f"File downloaded to: {local_file_name}")
else:
local_file_name = "../../config_postprocess_example.yml"
from musif.process.processor import DataProcessor
processed_df = DataProcessor(df,'../../config_postprocess_example.yml',
).process().data
Post-processing data...
# with `.shape` you can see the number of rows and columns of the dataframe
print('Shape post-processed df: ', processed_df.shape)
Shape post-processed df: (175, 585)
Now we have ‘processed_df’, a DataFrame that synthesizes the extracted information by deleting and/or combining columns of the extracted df. We can adjust and modify post-processing parameters by changing the yaml file file or by inserting key-value arguments. That way we can choose which columns we desire to be deleted or modified in order to introduce processed_df to further experiments.
Statistical processing¶
Let’s try to classify the features. We will setup a feature-learning approach with an autoencoder architecture.
For this, we will use sklearn and its Multilayer Perceptron, so you will need to install scikit-learn and seaborn packages in your anaconda environment.
In the next cell, the topic becomes a little more technical, but it’s just an example to show that you can use this DataFrame for statistical analysis. We will first remove redundant information (the FileName and the Id columns that were automatically assigned by the FeatureExtractor).
Then, we will create a model which:
Assigns a number to each feature that has strings as values (
OrdinalEncoder).Standardizes the features to get comparable values.
Trains a simple feed-forward fully connected autoencoder with ReLU activations and LBGFS optimizer.
The objective is to learn a 2D space where the 396 extracted features can be represented without loosing information.
!pip install scikit-learn seaborn
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler, OrdinalEncoder
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_absolute_error
# removing FileName and Id
if 'FileName' in processed_df:
del processed_df['FileName']
if 'Id' in processed_df:
del processed_df['Id']
preprocessor = make_pipeline(
OrdinalEncoder(), # give a cardinal number to features that are categories
StandardScaler(), # subtract the mean and scale between -1 and +1
)
model = make_pipeline(
preprocessor,
MLPRegressor(
hidden_layer_sizes=(128, 32, 8, 2, 8, 32, 128, 396), # the output size is the same as the number of features
activation="relu",
solver="lbfgs",
max_iter=100,
tol=0.1,
random_state=934,
max_fun=10**6
# shuffle=True
)
)
y_true = preprocessor.fit_transform(processed_df)
# the next call will take some time...
model.fit(processed_df, y_true)
y_hat = model.predict(processed_df)
print(f"Mean Absolute Error: {mean_absolute_error(y_true, y_hat)}")
Mean Absolute Error: 0.49524726832323923
/opt/anaconda3/envs/musif_tutorials/lib/python3.10/site-packages/sklearn/neural_network/_multilayer_perceptron.py:545: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
self.n_iter_ = _check_optimize_result("lbfgs", opt_res, self.max_iter)
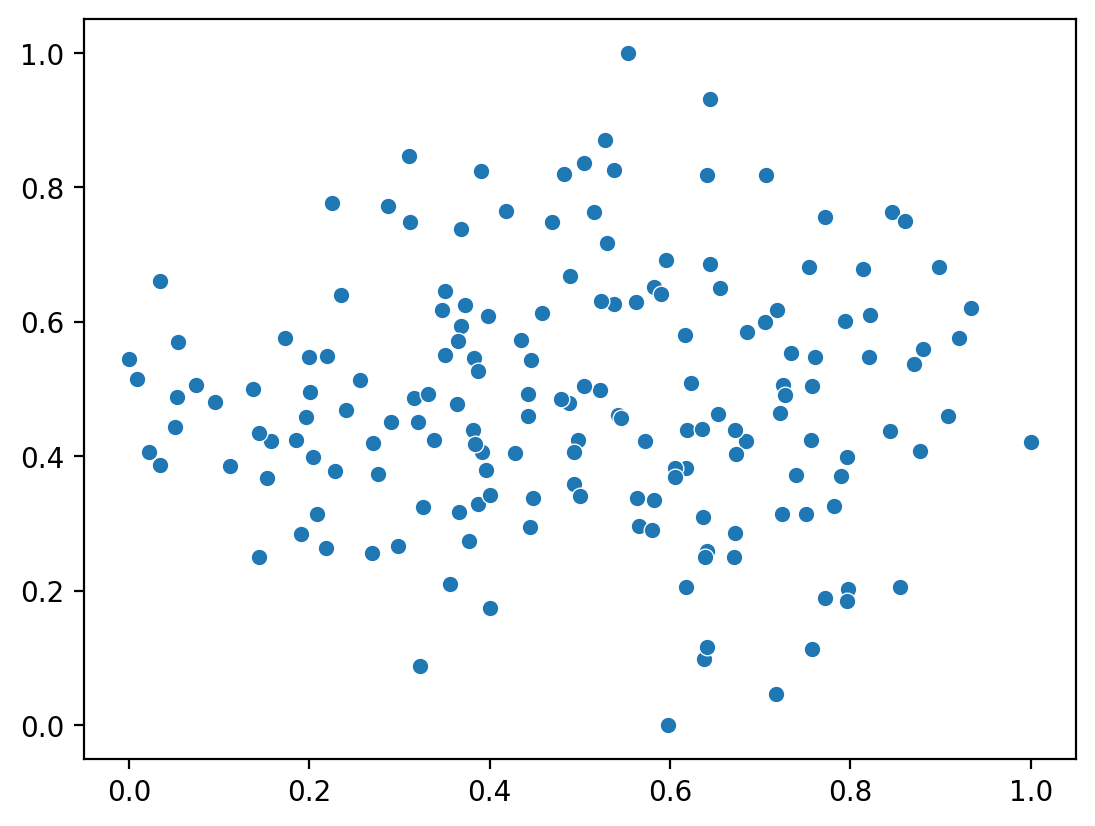
Now, we will attach a method transform to the MLPClassifier which returns the activations at the inner layer with 2 outputs, that we interpret as latent features. To compare the features, we will scale them in [0, 1].
Then, we plot the music scores according to the learned feature space.
from sklearn.preprocessing import MinMaxScaler
mlpclassifier = model['mlpregressor']
def mytransform_method(X):
activations = [None for _ in range(mlpclassifier.n_layers_)]
activations[0] = X
X = mlpclassifier._forward_pass(activations)[-6]
return MinMaxScaler().fit_transform(X)
mlpclassifier.transform = mytransform_method
learned_features = model.transform(processed_df)
learned_features.shape
(175, 2)
import seaborn
seaborn.scatterplot(x=learned_features[:, 0], y=learned_features[:, 1])
<Axes: >
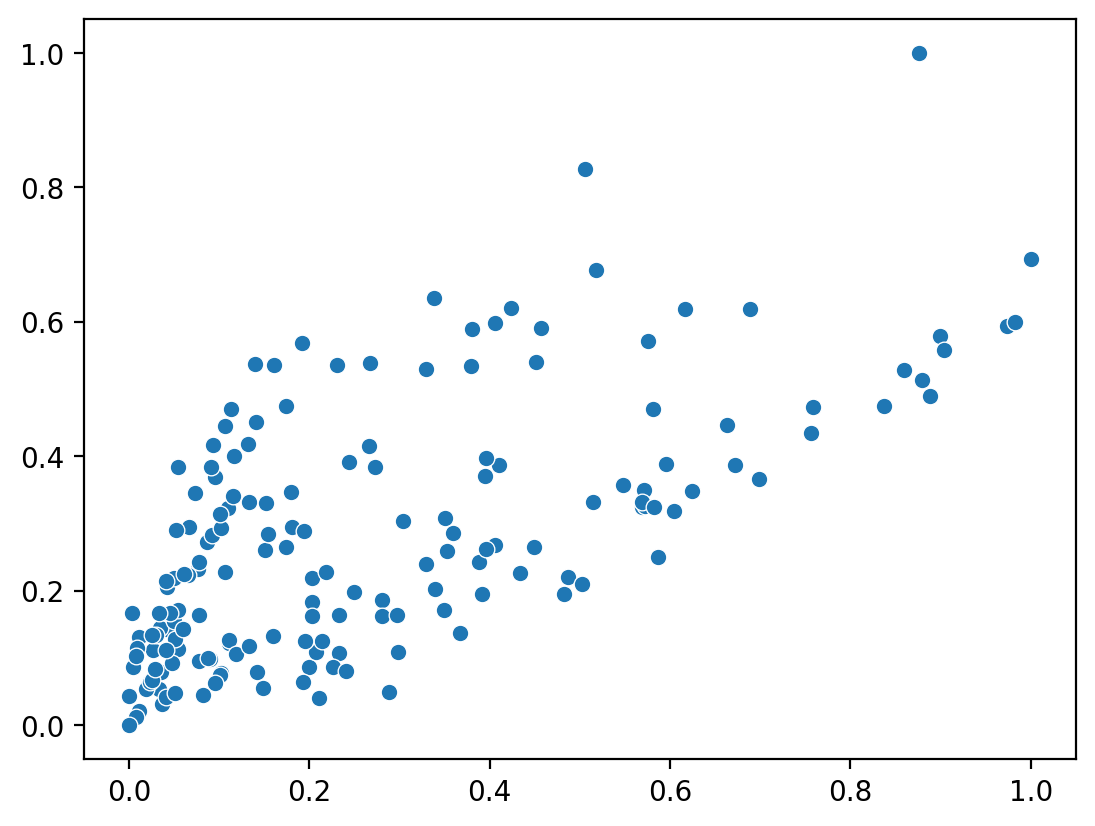
For comparison, let’s plot the 2D features learned by a standard PCA (the final scaler is aded to compare with the autoencoder):
from sklearn.decomposition import PCA
pca_pipeline = make_pipeline(
preprocessor, PCA(2), MinMaxScaler()
)
data_pca = pca_pipeline.fit_transform(processed_df)
ax = seaborn.scatterplot(x=data_pca[:, 0], y=data_pca[:, 1])